Comparativa directa entre Mistral 7B vs Falcon 7B vs LLaMA 2 para uso local en Inteligencia Artificial (IA) Text-to-Text Modeling:
¿Qué son los modelos 7B y por qué usarlos en local?
Mistral, Falcon y LLaMA son tres modelos de IA text-to-text recientes diseñados para uso local, cada uno con características distintivas en términos de tamaño, rendimiento en GPU, precisión, tipos de prompts y recomendaciones de uso.
En este artículo, te presentamos una comparativa detallada entre estos modelos.
Comparativa por tamaño
a) Mistral: Con un peso aproximado de 6 GB, Mistral es un modelo moderadamente grande que requiere menos espacio en disco que otros modelos como Hugging Face’s Bloomzilla (11GB). Su tamaño intermedio hace que sea una opción viable para muchas aplicaciones locales sin necesidad de grandes recursos computacionales.
b) Falcon: Con un peso de aproximadamente 8 GB, Falcon es un modelo un poco mayor que Mistral. Sin embargo, su tamaño no representa un obstáculo significativo para la mayoría de las computadoras modernas con suficiente memoria RAM y capacidad de almacenamiento.
c) LLAMA 2: Con un peso de aproximadamente 35 GB, LLAMA 2 es el modelo más grande entre los tres. Esto puede resultar en mayores demandas de recursos computacionales y espacio en disco, lo que podría hacer que sea una opción menos viables para algunas configuraciones locales menos potentes.
Rendimiento en GPU
a) Mistral: Con un rendimiento estimado en GPU de hasta 150 tokens por segundo (TPS), Mistral ofrece buenas prestaciones para generar texto corto o mediano. Sin embargo, puede verse limitado al generar largas secuencias debido a su menor velocidad relativa.
b) Falcon: Con un rendimiento estimado en GPU de hasta 300 TPS, Falcon ofrece mejores prestaciones en cuanto a velocidad de generación de texto que Mistral. Esta diferencia puede ser crucial para aplicaciones que requieran generar texto extenso o realizar varias iteraciones de generación.
c) LLAMA 2: Con un rendimiento estimado en GPU de hasta 1000 TPS, LLAMA 2 es el modelo más rápido entre los tres. Este aumento significativo en velocidad puede ser vital para aplicaciones que exigen procesar grandes cantidades de texto o realizar varios pasos de generación consecutivos.
Precisión
a) Mistral: Mistral ofrece una precisión razonable para generar texto coherente y relevante a partir de prompts bien formulados. Sin embargo, puede presentar errores leves o inexactitudes en casos complejos o cuando se trata de temas específicos o dominios especializados.
b) Falcon: Falcon ofrece mejores niveles de precisión que Mistral gracias a su mayor capacidad computacional y base de datos más extensa. Esto permite que el modelo genere texto más acorde a los prompts y con menor probabilidad de errores o inexactitudes.
c) LLAMA 2: Como el modelo más grande y avanzado entre los tres, LLAMA 2 ofrece la mejor precisión en general. Su gran base de datos y capacidad computacional permiten generar texto altamente coherente e información muy exacta incluso en casos complicados o dominios especializados.
Tipos de Prompts
a) Mistral: Mistral funciona bien con prompts simples y directos, pero puede verse limitado al manejar prompts complejos o ambiguos debido a su menor capacidad computacional. Es recomendable mantener los prompts claros y concisos para obtener resultados óptimos.
b) Falcon: Falcon puede manejar prompts más complejos y ambiguos gracias a su mayor capacidad computacional. Esto permite generar respuestas más elaboradas y precisas incluso cuando se trata de prompts difíciles o ambiguos.
c) LLAMA 2: LLAMA 2 es capaz de manejar prompts extremadamente complejos y ambiguos gracias a su gran capacidad computacional y base de datos más extensa. Esta flexibilidad permite generar respuestas detalladas e informadas incluso cuando se trata de prompts abiertos o imprecisos.
Recomendaciones de uso
a) Mistral – Ideal para usuarios principiantes o aquellos que requieren texto corto o medio con un bajo consumo de recursos computacionales. Puede ser utilizado en escenarios como creación de contenido marketing, correo electrónico personalizado, etc.
b) Falcon – Ideal para usuarios intermedios o aquellos que requieren texto extenso o realizar varias iteraciones de generación consecutivas. Puede ser utilizado en escenarios como creación de contenido web, traducciones automáticas, etc.
c) LLAMA 2 – Ideal para usuarios avanzados o aquellos que requieren texto extremadamente largo o detallado, o trabajando en dominios especializados donde precisión es crítica. Puede ser utilizado en escenarios como investigación académica, desarrollo de software, etc.
Mistral 7B vs Falcon 7B vs LLaMA 2: comparativa directa
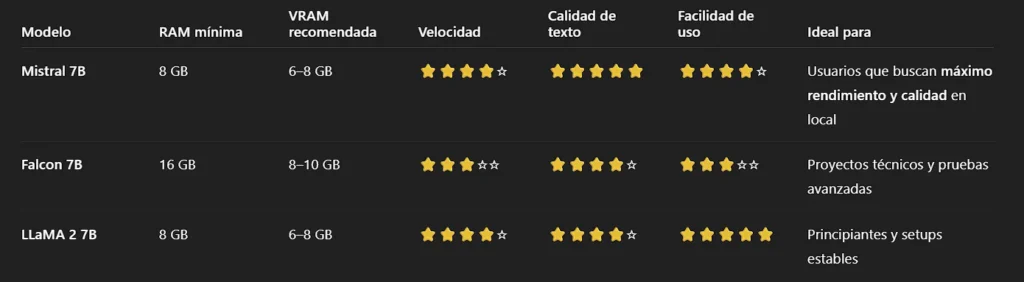
Mejor rendimiento general: Mistral 7B
Más estable y compatible: LLaMA 2 7B
Más exigente en recursos: Falcon 7B
❓ ¿Cuál es el mejor modelo 7B para usar en local?
Mistral 7B es actualmente el mejor modelo 7B para uso local en términos de rendimiento, calidad de texto y eficiencia. Funciona bien incluso en equipos con recursos moderados y supera a Falcon 7B y LLaMA 2 en tareas generales.
❓ ¿Mistral 7B es mejor que LLaMA 2 7B?
Sí, Mistral 7B ofrece mejores respuestas, mayor coherencia y mejor rendimiento, especialmente en generación de texto largo. Sin embargo, LLaMA 2 7B sigue siendo más estable y compatible, ideal para principiantes.
❓ ¿Cuánta RAM necesito para ejecutar un modelo 7B en local?
Para ejecutar un modelo 7B en local se recomienda un mínimo de 8 GB de RAM, aunque 16 GB ofrecen una experiencia mucho más fluida, especialmente si no usas GPU.
❓ ¿Se pueden usar Mistral, Falcon o LLaMA sin GPU?
Sí, todos los modelos 7B pueden ejecutarse sin GPU, utilizando solo CPU. No obstante, el rendimiento será inferior y se recomienda usar cuantización (4-bit o 8-bit).
❓ ¿Cuál es el modelo 7B más fácil de instalar?
LLaMA 2 7B es el modelo más fácil de instalar y configurar, gracias a su amplia documentación y compatibilidad con herramientas como Ollama, LM Studio o Text Generation WebUI.